top of page

LOW DOWN ON HIGH-ORDER BLOG
Blog: Headliner
Our Recent Posts




Archive
Tags

GPU Accelerated Gas Kinetic Simulation
The above movie is a visualization of a low Mach number gas kinetic simulation discretized with the D2Q9 Lattice Boltzmann Method solver...


Programming Languages, Tools, & Services
From my teaching experience at Rice University and at Virginia Tech I have observed that computationally inclined students benefit from a...
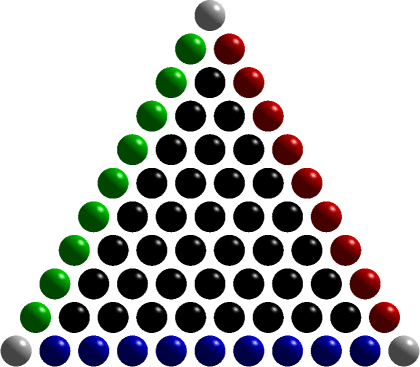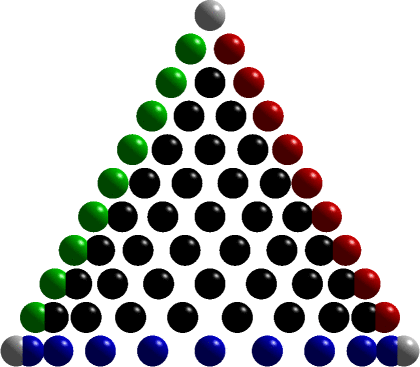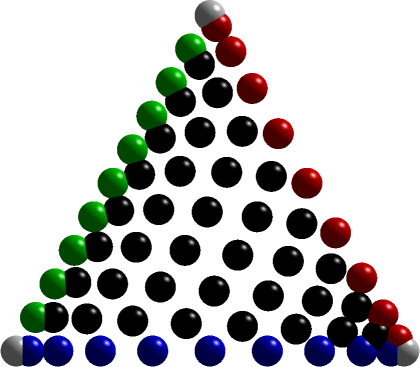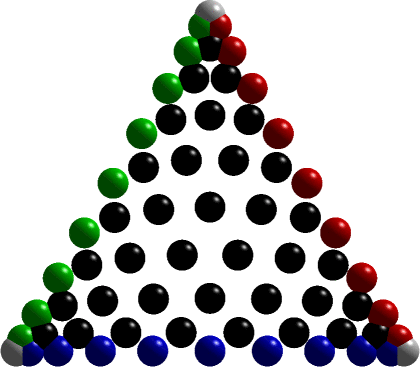
High-order Lagrange Elements: warp & blend nodes
Most of our finite element codes are built using the Warp & Blend Lagrange elements. The node distribution of these elements are...
ATPESC 18: applications now being accepted
The 2018 Argonne Training Program on Extreme Scale Computing is now accepting applications: link. This is an excellent opportunity to...
GPU Target Practice: Titan V
We have just ordered a sample NVIDIA Titan V GPU. This GPU has more than 5000 FP32 compute cores and theoretically delivers more than...



The Open Concurrent Computing Abstraction (OCCA): parallel computing on any processor
The Parallel Numerical Algorithms @VT research group relies heavily on the OCCA library to develop truly portable multithreading code...
Blog: Blog
bottom of page